


I still remember the first time I had to design a workflow for storing task events in Amazon Redshift from FTP sources. At first, it seemed simple: files come from FTP, data goes into Redshift, and everything works magically. But once I started thinking about real-world scenarios, it quickly became clear that there’s a lot more involved. Multiple files, different formats, scheduling, error handling—it’s a web of moving parts. That’s why understanding a redshift to store task events architecture diagram sample from ftp is essential for any data engineer or architect.
By the end of this guide, you’ll see exactly how to design a system that’s reliable, scalable, and easy to maintain. And if you’re curious about other architectural innovations in design, check out (link to Pascal Fabric Facade Designer Roho’s: Transforming Architecture with Textile Innovation).
Why Choose Redshift for Storing Task Events?
When you’re dealing with hundreds of thousands of task events every day, efficiency matters. Here’s why Redshift is a top choice:
1. Massive Scalability
Redshift handles huge datasets effortlessly. Whether events arrive in bursts or a steady stream, Redshift’s MPP (Massively Parallel Processing) architecture ensures the data load is smooth and quick.
2. High Performance
Columnar storage and parallel query processing mean analyzing vast amounts of task events is almost instantaneous. I’ve seen Redshift return results for millions of rows in seconds—a lifesaver during peak workload times.
3. Centralized Data Management
Instead of keeping logs scattered across multiple FTP servers, Redshift serves as a centralized warehouse. This makes analysis, reporting, and integration with BI tools seamless.
4. Security and Reliability
With built-in encryption at rest and in transit, Redshift ensures your task events are safe. Plus, proper ETL pipelines reduce the risk of missing or corrupted events.
5. Cost Efficiency
While Redshift isn’t free, its scalability and optimization features often make it more cost-effective than maintaining multiple on-premises databases.
Main Challenges in Storing Task Events from FTP
Before we dive into the step-by-step process, it’s important to understand common pain points:
- File inconsistencies: FTP sources often contain CSV, JSON, or XML files with varying structures.
- Duplicate or missing data: Without proper validation, you may load the same event multiple times or miss events entirely.
- Scheduling conflicts: Task events may arrive at unpredictable times, requiring careful automation.
- Transformation complexity: Parsing timestamps, handling null values, and standardizing formats can get tricky.
- Monitoring gaps: Without proper logging, failures can go unnoticed, causing data quality issues.
Recognizing these challenges early helps in designing a redshift to store task events architecture diagram sample from ftp that is robust and reliable.
Step-by-Step Guide: From FTP to Redshift
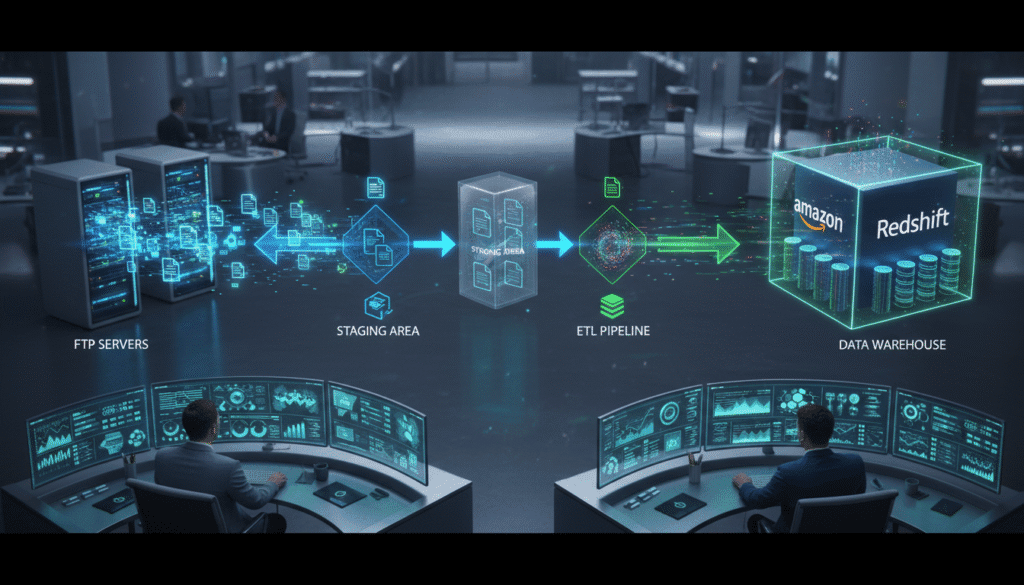
Step 1: Understanding the FTP Source
Before designing any architecture, get familiar with the FTP structure. Know the folders, file naming conventions, formats, and update schedules. I once worked on a project where a single folder contained mixed CSV and JSON files. Without proper mapping, ETL processes kept failing.
Step 2: Set Up Staging Storage
A staging area is crucial for validation. Typically, data from FTP is first copied to an intermediate storage like Amazon S3. This step ensures that files can be verified for integrity, checked for duplicates, and pre-processed before loading into Redshift.
Step 3: Designing Redshift Tables
Create a schema that reflects your task event structure. Consider primary keys, sort keys, and distribution style for performance. Choosing the wrong sort key, for example, can make queries much slower. In one of my earlier projects, fixing the sort key cut load times by more than half.
Step 4: Building the ETL Pipeline
Your ETL pipeline should extract, transform, and load data step by step:
- Extract files from FTP or staging storage.
- Validate for proper formatting, missing fields, and duplicates.
- Transform data (timestamps, formats, encoding).
- Load into Redshift tables.
A redshift to store task events architecture diagram sample from ftp typically shows a clear ETL flow from FTP → staging → transformation → Redshift → analytics.
Step 5: Automating the Process
Once the ETL works manually, automate it using tools like Airflow, cron jobs, or Lambda functions. Automation ensures that new task events are loaded in real-time or near-real-time, reducing manual intervention.
Step 6: Monitoring and Logging
Finally, a reliable architecture includes monitoring. Log every ETL job: successes, failures, and anomalies. Alerts can help prevent unnoticed issues. Personally, I like to include dashboards that show ingestion rates, failures, and data quality metrics.
Practical Tips for Implementation
- Validate Early: Always check FTP file integrity before loading.
- Use Staging Tables: Avoid loading raw files directly into final tables.
- Optimize Table Design: Correct sort and distribution keys are essential.
- Incremental Loads: Only process new data to save time and resources.
- Document the Architecture: Keep a clear diagram to explain the workflow.
Common FAQs
Q1: Can multiple FTP sources feed a single Redshift cluster?
Yes, but keep each source isolated in staging to avoid conflicts and simplify debugging.
Q2: Which file format is best for Redshift ingestion?
CSV is simple, but Parquet or JSON may reduce storage costs and improve performance.
Q3: How do I handle failed ETL jobs?
Keep error files in a separate folder and set up alerts for immediate resolution.
Q4: Should task events have a dedicated schema?
Yes, this makes maintenance easier and keeps event tables organized.
Q5: How can I visualize the architecture?
Draw a diagram showing FTP sources → staging (S3) → ETL → Redshift → BI tools. This clarifies workflow for teams and stakeholders.
Conclusion: Make Task Event Storage Simple and Reliable
Storing task events from FTP in Redshift might seem daunting at first, but breaking it down step by step makes it manageable. From understanding the FTP structure to designing Redshift tables, implementing ETL, automating, and monitoring, each stage is essential.
A redshift to store task events architecture diagram sample from ftp ensures your workflow is scalable, reliable, and easy to maintain. For inspiration on other architectural innovations, check out (link to Pascal Fabric Facade Designer Roho’s: Transforming Architecture with Textile Innovation).
With a clear design, proper tools, and automation, storing and analyzing task events can be seamless and efficient.